
Unlocking the Power of Neural Networks in Embedded Systems
22 August 2023
22 August 2023
Neural networks and resource-constrained embedded systems may sound like oil and water. However, when combined correctly, these technologies have the potential to open up a realm of incredible opportunities in the industry. In this article, we aim to demystify neural networks shedding light on how they can reshape the future of embedded devices.
The global neural network market is booming. In 2020, its value reached $14.35 billion and might be reaching $152.61 billion by 2030. Neural networks have been receiving a lot of attention from the general public in recent years. However, the idea is over 80 years old. It was first proposed in 1944 by Warren McCullough and Walter Pitts, two University of Chicago researchers. While they worked in the field of neurology rather than technology, their study clearly showed similarities between the human brain and computer devices.
Today, neural networks are dispersing into more and more areas of modern life, from computer vision and speech recognition to targeted advertising. It’s not surprising that AI has also become one of the main trends in embedded systems this year. But what exactly do neural networks bring to embedded? Let’s dive in.


Neural networks, also known as artificial neural networks (ANNs), are a subfield of machine learning and lie at the core of deep learning. They use a series of algorithms to process the data in a way that is inspired by the structure and function of the human brain.
At a basic level, a neural network usually consists of three node layers: an input layer, one or more hidden layers and an output layer, as perfectly illustrated in the graphic by IBM. Each node possesses a weight and threshold. When the output of a certain node exceeds the threshold, the data is sent to the next layer of the network. If not, the node stays inactive and the data is not passed along.
Neural networks process data gathered from sensors or provided directly by a software engineer. This data may include images, texts or sounds, which are converted into numerical values.
To classify the data, we must train a neural network beforehand. Initially, all nodes have random weights and thresholds. During the training phase, we provide the network with example data. It learns to recognize patterns and tries to categorize them.
Its predictions may be right or wrong, and it’s the role of the programmer to correct them. As the network learns from its mistakes, its guesses gradually improve until they reach a satisfactory point. In other words, the weights and thresholds are continually adjusted until the training data with the same labels consistently produces similar outputs.
Once the
training of a neural network completes, it becomes a powerful tool allowing us
to classify data at high speed. As a result, tasks that would require hours of human effort, can be performed within minutes. What’s more, bringing neural networks to embedded systems, close to where data is generated, has even more advantages.
Undeniably, applying neural networks at the edge, where sensors gather data, comes with numerous benefits including increased reliability, low latency, enhanced privacy and energy optimization. Unlike traditional models, neural networks can immediately process large amounts of unstructured data generated by sensors and perform accurate real-time analysis.
Yet, implementing neural networks in embedded systems doesn’t come without challenges. Firstly, neural networks depend heavily on the quality of data they are trained on. If you provide a neural network with a biased dataset, the network will be biased as well.
Secondly, neural networks are both computationally and memory intensive. So, the process of running training directly on embedded devices can be extremely time-consuming.
As embedded devices are typically resource-constrained, training and inference, that is the deployment of neural networks, occur on different platforms. Usually, we would perform training offline on desktops or in the cloud by feeding large labeled datasets into neural networks. Then, such a trained neural network can be deployed on an embedded device that will execute the algorithm to perform a specific task.
Still, fine-tuning the algorithms may require days or even weeks. Let’s explore how we can accelerate this process.
There are numerous techniques that allow us to create smaller and less computationally intensive neural networks. We’ll have a closer look at two of them: model pruning and quantization.
Model pruning removes unimportant weights to get smaller and faster networks that can be trained again until they reach a satisfactory performance. A three-step method introduced by Han et al. (2015) consists of training a neural network, pruning connections with weights lower than a chosen threshold and retraining the network to optimize the weights of the remaining connections. We choose the treshold according to the sensitivity of each layer, as shown in the figure below.
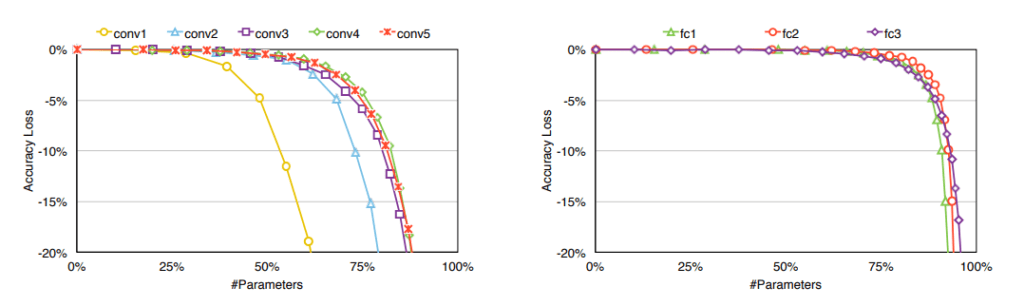
Although the study needed 173 hours to retrain the pruned network, the method reduced the number of parameters of AlexNet architecture nine times, from 61 million to 6.7 million, without loss in accuracy. Consequently, such neural network architecture requires much less memory and you can store it on a chip.
Instead of reducing the number of computations within the network, quantization reduces the precision of the weights, biases and activations so that the bit width of the data storage is minimized. This allows for quicker inference, lower network latency and reduced energy consumption. Neural networks usually use 32-bit floats to represent the parameters. Quantization converts them to smaller representations, such as 8-bit integers.
However, one tradeoff can be the loss in accuracy as the neural networks may not represent the information precisely. Yet, studies show that, depending on network architecture and quantization scheme, quantization may result in a minimal loss of accuracy.
To facilitate and accelerate the training of neural networks, we can use frameworks dedicated to deep learning. These platforms provide us with built-in datasets, reusable code blocks and useful modules for model development.
Among the most popular neural network frameworks are TensorFlow, an open-source project from Google, MxNet, ONNX and PyTorch.
Inference frameworks, such as TensorFlow Lite, also let us optimize our models to run on a variety of embedded devices and find the right model size, inference speed and the quality of the predictions.
Undoubtedly, the choice of the right hardware platform for running neural networks will largely depend on your project requirements. However, we would generally recommend focusing on the scope of application, processing performance, ease of use and power consumption.
Generally, one of the most effective ways to improve computing performance and power efficiency is the use of a neural processing unit (NPU) also called an AI/ML accelerator.
Simply put, NPU is a microprocessor that specializes in accelerating machine learning algorithms. It executes neural networks in an energy-efficient way that reduces inference time and power consumption. As a result, some claim that NPUs are tens or even thousands of times faster and more efficient than traditional CPUs for training and inference of AI algorithms.
As the microprocessor and microcontroller markets are developing rapidly, more and more hardware platforms in the market come equipped with built-in NPUs optimized for neural networks. Furthermore, the emerging field within AI, TinyML is even bringing neural networks to microcontrollers.
So, let’s have a look at two example platforms optimized for neural network applications:
Measuring just 70x45mm, NVidia Jetson Nano is a compact computer for embedded AI applications. It offers 472 GFLOPS of compute performance with a quad-core 64-bit ARM CPU and a 128-core integrated NVIDIA GPU, 4GB LPDDR4 memory and 5W/10W power modes. It can run multiple neural networks in parallel and processes several high-resolution sensors simultaneously.

SpaceSOM-8Mplus from SoMLabs is a SoM optimized for machine learning, artificial intelligence and neural networks. According to the manufacturer, it’s based on the NXP iMX8Mplus processor which features an ARM Cortex-A53 quad core with speed up to 1.8GHz along with an ARM Cortex-M7 as well as an advanced NPU and 3D GPU.

Both are compact but powerful platforms with smart capabilities in data processing. While Nvidia Jetson Nano is a well-established product dedicated to image processing, SpaceSOM-8Mplus is a newer and less expensive alternative suited for general applications.
New fields of applications of neural networks in embedded systems and IoT are emerging rapidly. Let’s have a look at some examples.
Leveraging neural networks and embedded devices allows healthcare organizations to deliver better care at a reduced cost. In fact, such inventions are useful in detecting diseases, predicting the risk of future diseases, health monitoring and predicting missing clinical data among others.
For example, a 5G-Smart Diabetes system that combines wearable devices, neural networks and big data can predict a patient’s risk of diabetes and provide effective personalized diagnosis and treatment recommendations.
Another real-time monitoring system can determine a patient’s condition by gathering sensor readings such as facial expressions, speech, EEG, movements and gestures. Next, neural networks classify these signals and the system notifies the healthcare personnel in case of emergency.
Neural networks are transforming the industry 4.0 enhancing predictive maintenance and quality control. Particularly, one example is a manufacturing inspection system based on neural networks that can classify manufactured products as defective and non-defective. In some cases, systems are even able to determine the type and degree of defect.
Implementing neural networks in embedded and IoT technologies enables efficient, reliable and most importantly safer transportation. Beyond the most prominent example of self-driving cars, applications also include traffic congestion management, traffic speed prediction, obstacle detection, and accident detection.
One study has demonstrated that model based on neural networks can forecast traffic congestion through the analysis of GPS data. The model learns the traffic as images with two dimensions, time and space and achieves an accuracy of over 88%.
Self-driving vehicles use several dozen of sensors and generate even up to 4 terabytes of data per day. Then, neural networks process this data in real time to analyze the environment, predict the actions of the objects and vehicles near it and make autonomous decisions.
We’re thrilled to see more and more embedded systems incorporating the concept of neural networks. Undoubtedly, the combination of both technologies holds the promise of unlocking new levels of intelligence and autonomy within embedded devices. We can anticipate the future where devices seamlessly learn, adapt, and make intelligent decisions in real time.


By Piotr Kubaty